AI · 3 min
Attention Mechanism : The Secret Behind How Transformers Think

Amrutha Satishkumar
February 20, 2026
Last week, I wrote about Transformers, the architecture that changed the trajectory of modern AI.
But this week, I dug into the real reason why they work so well.
If Transformers are the brain of AI, the attention mechanism is the thought process that makes them intelligent. It’s the part that decides for every single word and identify what’s important, what’s not, and how everything connects.
And the more I learned, the more it clicked: Attention isn’t just one feature inside Transformers. It is what defines the Transformer.
How Attention Fits Inside the Transformer?
Traditional models like RNNs and LSTMs read text word by word, building understanding gradually like reading a sentence out loud. Transformers replaced that linear approach with something radically different: Self-Attention.
In a Transformer, every input token compares itself to every other token to figure out what it should pay attention to.
Instead of learning meaning from sequence order, it learns meaning from relationships.
So when the model reads a sentence like:
“The animal didn’t cross the street because it was too tired.”
It doesn’t just memorize word positions it learns that “it” most likely refers to “the animal,” not “the street.”
That ability to dynamically understand context is what made Transformers outperform everything before them.
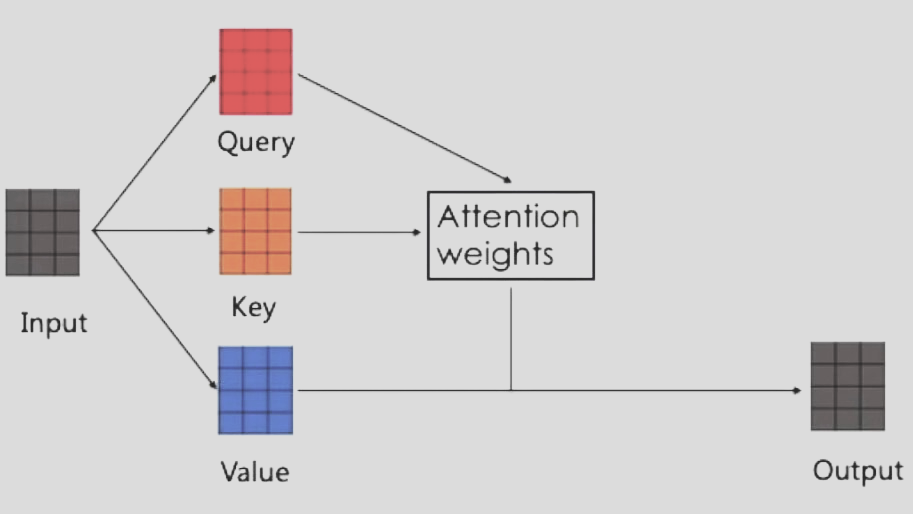
The Components : Queries, Keys, and Values
The attention mechanism relies on three simple components: Query (Q), Key (K), and Value (V). When I first came across these terms, they sounded confusingly abstract. But they actually come from a very intuitive idea that is “search and retrieval”.
Imagine you’re in a library.
-
The query (Q) is what you’re looking for.
-
The keys (K) are labels on the books.
-
The values (V) are the actual content inside each book.
The attention mechanism matches the query with all the keys to find which books (words) are most relevant and then retrieves the corresponding values.
Image from Google.com
Each word in a sentence acts as a query to every other word computing similarity scores and weighting their influence accordingly. The result is an attention matrix showing how strongly each token “attends” to others.
That’s how the Transformer builds contextual meaning, not through order, but through attention patterns.
Self-Attention and Cross-Attention
As I went deeper into the course, I learned that there are different ways models apply attention:
-
Self-Attention: Used in both encoders and decoders, where every token looks at all other tokens in the same sequence to build understanding. Example: Understanding the meaning of “bank” differently in “river bank” vs. “money bank.”
-
Cross-Attention: Used in encoder-decoder models, where the decoder attends to the encoder’s output instead of its own input. Example: Translating English to French the decoder looks back at the encoder’s representations to align words correctly.
In short:
-
Self-attention helps the model understand itself.
-
Cross-attention helps the model understand others.
Together, they form the basis for everything from BERT to GPT to T5.
Multi-Head Attention : The Parallel Thinker
One downside is that the language is complex. In a single sentence, we might want to look at subject-verb relationships, emotional tone, and references all at once.
One “head” of attention might focus on one kind of relationship say, subject-verb agreement but another might focus on adjectives or sentence boundaries.
That’s why Transformers use Multi-Head Attention, and it allows the model to capture multiple relationships simultaneously.
Each head looks at the same input from a different angle like multiple people reading the same paragraph but focusing on different details. Their combined view gives the model a richer, more complete understanding.
That’s what gives Transformers such depth and nuance. They don’t just read text they analyze it in parallel.
My Takeaway
After spending this week studying the Attention Mechanism, I think I finally get why it’s called self-attention.
Every word, every token, every embedding contributes to building meaning, and the model learns to weight those relationships dynamically.
That’s why this concept became the backbone of everything from BERT to GPT to T5.
It’s what allows LLMs to:
-
Remember long-range dependencies
-
Understand context
-
Generate coherent, human-like text
The Transformer wasn’t just a new model, it was a new way of thinking.
It taught machines how to focus.
Next week, I’ll be diving into Positional Encoding, the trick that lets Transformers understand order even though they process everything at once.
Amrutha Satishkumar
Data & AI Solution Engineer at Microsoft


