AI · 3 min
Feed-Forward Networks: How Transformers Refine What They Learn

Amrutha Satishkumar
February 20, 2026
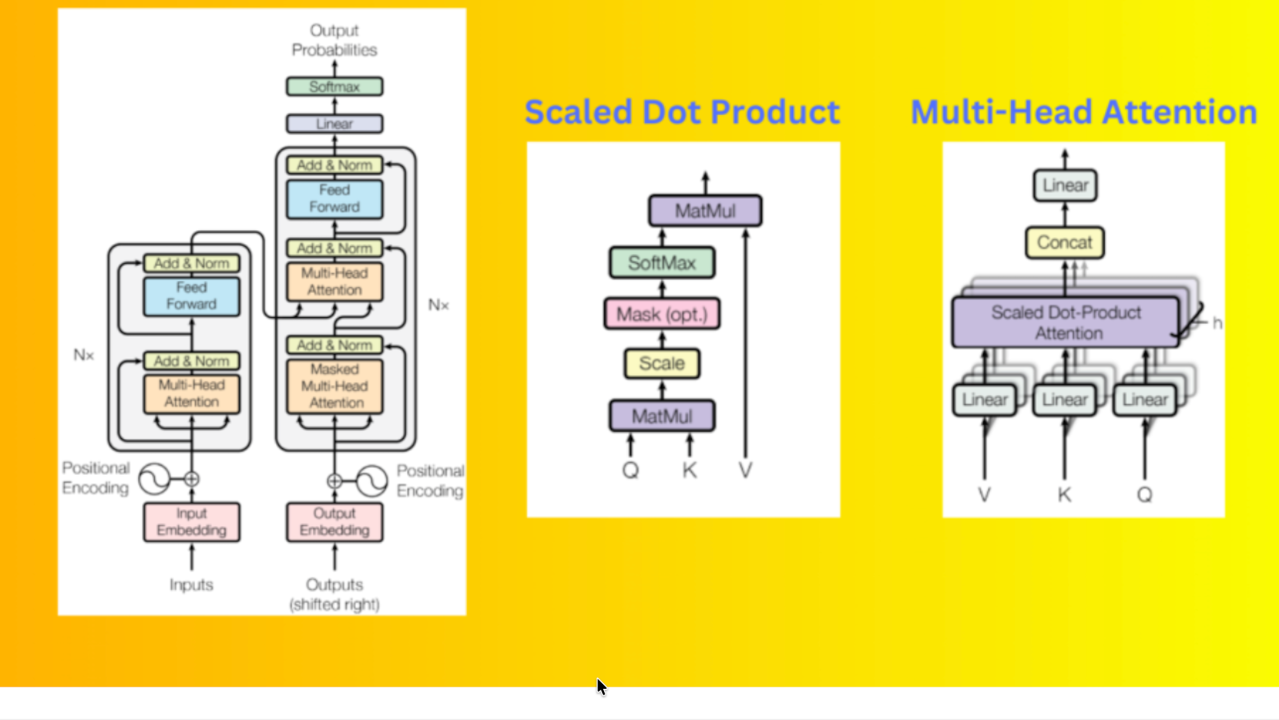
In my last few articles, I’ve explored some of the most important pieces of the Transformer architecture : Attention, Positional Encoding, and Multi-Head Attention.
Each of these mechanisms helps a Transformer understand relationships, structure, and meaning. But there’s one final piece I’ve been learning about that often goes unnoticed, yet plays a crucial role:
Feed-Forward Networks (FFN) is the layer that transforms raw attention outputs into deeper, more meaningful representations.
It may not sound as exciting as attention, but without it, Transformers wouldn’t be able to generalize, reason, or build the hierarchical understanding that makes them so powerful.
Why Attention Isn’t Enough
Attention mechanisms help the model decide what matters which words influence which. But attention alone doesn’t fully shape or refine these signals.
It’s similar to reading a paragraph and noticing important phrases which could be called attention. But then your brain interprets what those phrases mean, connects them, and forms understanding and that’s the role of the FFN.
Feed-forward networks are how the Transformer turns raw relevance into understanding.
What Feed-Forward Networks Actually Do (Conceptually)
Every Transformer layer has an FFN that sits right after the attention mechanism. And interestingly, it’s applied independently to every token, using the same transformation each time.
You can think of it as a small “thinking step” the model takes for each word, after learning its context through attention.
Here’s what happens intuitively:
-
The model expands the representation almost like zooming out to explore richer features.
-
It applies a nonlinearity this is where the model learns patterns it couldn’t capture through attention alone.
-
It compresses the representation back down this helps the model retain only the most meaningful refinements.
It’s a simple two-layer transformation repeated across every token, but it’s what gives the model depth. Attention finds relationships. The FFN turns those relationships into concepts.
How FFNs Shape Meaning
What surprised me is how much of a model’s reasoning happens here. While attention handles interactions,
FFNs:
-
Build abstract features
-
Detect patterns that aren’t directly relational
-
Refine information layer after layer
-
Give the model the ability to generalize
In many ways, this is where the Transformer starts moving beyond pattern matching and toward real comprehension.
The FFN is also why stacking Transformer layers works so well :
Each layer’s attention learns new relationships, and each FFN transforms those insights into richer representations.
After several layers, the model doesn’t just know which tokens relate it understands why.
Why This Matters
Before learning this, I used to picture the Transformer as mostly “attention with some extras.”
Now I understand the architecture differently:
Attention tells the model what to look at, but the feed-forward network is where meaning is refined.
It’s the quiet step simple, consistent, and applied to every token but it’s the part that turns relational signals into actual understanding.
It’s also why Transformers can stack dozens (or even hundreds) of layers and still improve each FFN builds on the last layer’s insights, progressively shaping the model’s internal representation of the world.
My Takeaway
Exploring Transformers piece by piece has shifted my understanding of modern AI structures. What impresses me the most is how simple ideas focusing on relevant tokens, encoding order, viewing context from multiple perspectives all come together through a transformation step as straightforward as a feed-forward network.
Transformers taught machines how to focus, connect, and interpret and in doing so, transformed AI itself.
This marks the end of my foundational series on Transformers the architecture that changed the trajectory of AI.Understanding how these pieces fit together has been incredibly insightful, and it gave me a much clearer view of how LLMs actually work under the hood. You can find the rest of the series on my articles if you’d like to understand the full architecture.
Amrutha Satishkumar
Data & AI Solution Engineer at Microsoft


